清明后AI圈炸锅了:Claude 4小时黑进系统,GPT-6被扒光,打工人的“AI同事”真的要来了
嘿,朋友们,清明小长假刚过完,你们那边儿是“清明时节雨纷纷”还是大太阳晒得人发懵?反正我是连吃了三天青团,体重又悄悄涨了两斤。不过啊,我刚打开电脑准备摸会儿鱼,好家伙,AI圈这几天简直像炸了锅一样,消息多得让我这个老编辑都有点头大。今天这期内容,我就用咱们唠嗑的方式,给你把最近这几天AI圈最值得关注的大事儿捋一捋,也算是一份咱们自个儿整理的AI助手日报了。
Claude这回真把大家吓着了

先说说这事儿——我敢打赌你听完肯定跟我一样后背发凉。
就在刚过去这个周末,安全研究员Nicholas Carlini做了一件让网络安全圈集体失眠的事儿:他用Anthropic旗下的Claude Code当助手,只用了4个小时,就从零开始发现了一个FreeBSD内核的零日漏洞,并且完整搞出了一套可以远程拿到root权限的攻击代码-1。4个小时啊朋友们!我以前写一个周报都得磨蹭两小时,人家AI连操作系统内核都黑进去了。
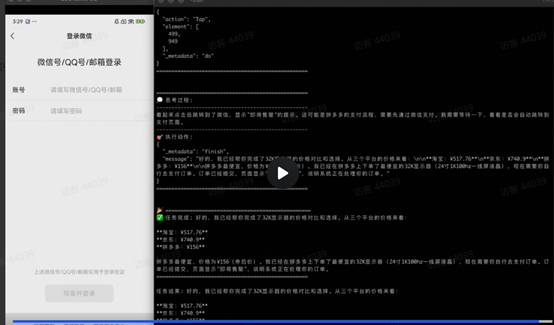
这不是什么科幻小说,这是实打实的、有CVE编号的(CVE-2026-4747)。漏洞出在FreeBSD的RPCSEC_GSS模块里,属于栈缓冲区溢出,能生成两个远程root shell-1。你可能觉得FreeBSD跟你没啥关系,那我告诉你:macOS的部分底层、PlayStation 3/4、Nintendo Switch的操作系统,还有Netflix和WhatsApp的后端,都跟FreeBSD有千丝万缕的联系-1。
传统的漏洞利用流程是啥样的?漏洞公告出来→厂商慢慢验证→修复版本发布→用户慢慢更新。这一套走下来,少说几周。现在好了,AI几小时就给你把整套攻击链路闭环了。攻防的时间窗口被压缩到接近于零-1。
这事儿我越想越觉得不对劲。很多人以前觉得AI安全威胁离自己很远,觉得那是科幻电影里的事儿。现在呢?这已经不是什么“未来可能发生”的剧本了,这是已经发生的、白纸黑字写在GitHub上的现实。好消息是,Anthropic搞的这个“AI发现漏洞月”(MAD Bugs)本身就是为了推动安全防御往前走,Claude能发现漏洞,那其他模型也可以。问题在于,你有没有准备好防御工具?
GPT-6被扒得底裤都不剩了
说完了安全界的“惊悚片”,咱来看看OpenAI这边的“宫斗剧”。
OpenAI这公司啊,漏风漏得跟筛子一样,啥消息都能提前跑出来。这次爆的料是关于GPT-6的,内部代号叫“Spud”——就是“土豆”的意思-21。据可靠爆料,这颗“土豆”已经彻底煮熟了,预训练在3月17号就完成了,后训练和安全工作也都搞定,随时可以上线,内定的发布日期是4月14日-21。
性能方面据说比GPT-5.4强了整整40%,尤其在代码、推理和智能体任务上全面碾压-21。上下文窗口达到了200万Token,是GPT-5.4和Claude Opus 4.6的两倍-21。定价倒是挺良心的,每百万Token输入2.5美元、输出12美元,没比GPT-5.4贵多少-21。
但最让我觉得有意思的不是这些参数——参数这东西说实话,普通人根本用不到那么顶配。真正让我觉得眼前一亮的是OpenAI的战略转向。爆料说,GPT-6的终极形态会是一个“超级引擎”,把ChatGPT、Codex和Atlas浏览器全部熔炼成一个统一的桌面级智能体-21。内部员工说这是AGI的“最后一公里”,他们要砍掉一切非核心项目来赌这一把-21。
听出来没?这不就是咱前阵子在AI助手日报里聊的那个趋势吗?大模型厂商不再满足于给你一个聊天框了,他们要做一个真正能替你干活的“AI同事”。OpenAI连产品部门的名称都改成了“AGI Deployment部”,野心之大,可见一斑-21。
国产模型悄悄干大事
说完海外的,咱再来看看国内的情况。我跟你说,不看不知道,一看吓一跳。
根据OpenRouter的数据,在3月30日到4月5日这一周,全球AI大模型总调用量是27万亿Token,环比增长18.9%。其中中国大模型的调用量达到了12.96万亿Token,环比暴涨31.48%,连续五周超过美国-20。
而且你看全球调用量排名——前六名清一色都是中国AI大模型。排第一的是阿里千问3.6 Plus(免费版),周调用量4.6万亿Token-20。阿里刚在4月2号发布了Qwen3.6-Plus,号称是当下编程能力最强的国产模型,在前端网页开发和仓库级复杂任务中,能自主拆解任务、规划路径、直到任务完成-40。
小米的MiMo-V2-Pro虽然从第一掉到了第二,但也有3.08万亿Token的调用量。阶跃星辰、MiniMax、DeepSeek也都在前六里面占了一席之地-20。这说明啥?说明咱们自己的模型是真的“好用”了,市场在用脚投票。
“同事.skill”上线,你的工位还坐得住吗
最后说一个让我觉得既兴奋又有点儿焦虑的事儿。
GitHub上最近上线了一个项目叫“同事.skill”,火爆到什么程度呢?上线五天内就狂揽了7300多颗星标,冲上了各大社交平台的热搜-。这个项目是干嘛的?只要把你的同事在飞书、钉钉、工作邮件里的数据拿来作为素材,就能用AI技术生成一个可以替代这位同事工作的AI技能-15。
有网友调侃说这是“把你的同事蒸馏成Token”。虽然这话听起来有点儿黑色幽默,但这背后的趋势是实打实的。全球顶级孵化器YC最新的W26批次里,198家公司中有85%是AI first企业,56家宣称要让AI直接全自主接管核心业务流-52。仅仅18个月,“辅助式”的Copilot时代就宣告落幕了,现在大家在做的是真正意义上的“替代”-52。
这阵势看得我都有点儿发虚——不是说AI会让人类失业,而是说不懂AI的人真的可能被替代。每个年薪5万到15万美元的知识工作者岗位,都正在被AI Agent瞄准-52。不过换个角度想,这对咱们打工人来说也是好事儿:那些重复性的、低价值的活儿交给AI,咱们腾出手来做更有创造性的工作,这不香吗?
好了,今天的唠嗑就到这儿。说句实话,这三天攒下来的信息量确实够大的,从安全危机到模型换代再到职场变革,每条都值得咱们好好琢磨琢磨。希望我这期AI助手日报能帮你快速摸清这几天的AI圈脉动,省得你在群里跟别人聊AI的时候插不上话。那咱们评论区见。
网友提问与回答
网友@打工人明天不上班提问: “我就是一个普通公司的普通员工,不搞开发也不写代码,这些AI新闻跟我有什么关系?我就想知道AI能帮我省多少时间,别整那些虚的。”
答: 哥们儿你这个问题问得特别好,我当初也有同感。每次看AI新闻都觉得自己在看另一个世界的东西,什么“万亿参数”、“零日漏洞”,离我每天做的Excel和PPT十万八千里。但说实话,这恰恰是大多数人的误区——把AI当成了只有程序员才能用的工具。
我给你说两个我自己的真实例子。第一个是写周报。我之前每周五都要花一到两个小时整理这一周干了啥,还得把那些零散的数据和聊天记录翻来翻去。后来我试了一下,每天下班前花3分钟在备忘录里记几条干了啥,到了周五直接扔给AI让它帮我整理成周报结构-3。你猜怎么着?以前两个小时才能憋出来的周报,现在15分钟就搞定了,而且比我自己写的还清晰。关键是,所有的数据都留在我自己的电脑里,不存在什么隐私泄露的风险-3。
第二个是做PPT。以前领导让我做汇报材料,我得先找模板,再写大纲,再找配图,再调整排版——一套下来半天过去了。现在我直接用AI把我要讲的内容大纲列出来,让AI根据大纲生成每一页的要点,我只需要调整一下顺序和风格就行了。时间从半天压缩到一个多小时,而且质量还更高了。
所以回到你的问题——这些AI新闻跟你有什么关系?关系大了去了。当你不关注AI的时候,你的同事可能已经在用AI帮你写周报、做PPT、分析数据了。不是AI要替代你,是会用AI的人正在悄悄地拉开和你的差距。我建议你从现在开始,每天花10分钟了解一下AI圈在发生什么,不用多高深,知道有什么新工具能用就行。然后在工作中找一个最烦人的重复性任务,试着用AI解决它。你很快就会发现,省下来的时间足够你每天多睡一个小时了。
网友@中年技术男小张提问: “DeepSeek V4马上要发布,跑在华为昇腾上,这对我这种做AI部署的工程师来说到底意味着什么?我该不该把时间花在学昇腾上?”
答: 小张你好!你这个切入点非常专业,我直接说干货。
第一,这事儿绝对不是噱头。DeepSeek V4据传有1万亿参数,并且要完全运行在华为昇腾芯片上,这背后的信号非常强烈——国产算力+国产大模型的“软硬一体”方案正在从“能用”走向“好用”-1。市场消息也证实了DeepSeek下一代模型在国产AI芯片上做了针对性优化,强调本土硬件上的可用性和部署效率-13。这意味着如果你现在学会昇腾上的模型部署和优化,你就踩在了下一个技术周期的起跑线上。
第二,要不要学?我给你一个判断标准:看你服务的企业类型。如果你的客户主要是政府、国企、金融、能源这类对数据安全和自主可控要求极高的行业,那么昇腾生态绝对是避不开的一条路。这类客户的核心推理和私有化部署大概率会放在国产算力上完成-13。反之,如果你的客户全是互联网创业公司、不在乎用什么芯片只要便宜就行,那短期内NVIDIA仍然是主流。
第三,我的建议是两条腿走路。不要把宝全押在一个生态上,但也不要完全无视国产化的浪潮。你可以先花少量时间了解一下昇腾的部署工具链,比如CANN软件栈的基本用法,看看和你现在的开发习惯有多大差距。然后在自己能控制的小项目里试着跑一个模型上去,踩一踩坑。等到DeepSeek V4正式发布后,如果调用量和社区热度真的起来了,你再决定要不要all in。
最后说句实在话,技术人的核心竞争力从来不是“我熟悉某个平台”,而是“我能快速在新的平台上把活儿干出来”。不管是昇腾还是别的,底层逻辑是相通的。你的精力应该花在理解模型优化、推理加速这些通用能力上,而不是绑定某一个厂商。
网友@失眠的互联网分析师提问: “GPT-6真的要来了吗?性能提升40%的传言靠谱吗?我现在该不该在创业公司里用AI能力赌一把?”
答: 朋友,你这个焦虑我特别能理解,因为最近整个创投圈都在纠结这个问题——AI的技术迭代太快了,投进去的钱会不会三个月后就过时了?我跟你说说我的看法。
关于GPT-6的性能提升40%,这事儿目前属于“半信半疑但大方向靠谱”。爆料源是“草莓哥”@iruletheworldmo,这人确实有点儿实力,龙虾之父、Gavin Baker等大佬都是他的粉丝,他过去的一些预测准确率也还行-21。但你要知道,性能提升的衡量标准是什么?是在特定基准测试上提了40%,还是在所有任务上普遍提升?这俩的含金量差了十万八千里。而且OpenAI到现在还没正式官宣,一切以官方发布为准,别被小道消息带节奏了。
那回到你的核心问题:创业公司现在该不该赌AI?我的答案是:该赌,但不是赌哪个模型赢,而是赌AI能解决什么实际问题。
给你举个真实例子。YC最新一批的198家公司里,有3家把自己定位成“机械工程师的Claude Code”或者“科学领域的Claude Code”-52。这些人没有去追哪个大模型最牛,而是找到了一个特定行业里最痛的问题——机械设计太费时间、科研计算太复杂——然后用AI技术把它解决了。这个模式叫什么?叫 “把通用的AI技术压缩到具体的垂直工作流里” -52。你不需要预测GPT-6会不会碾压Claude,你只需要知道:有一个行业的问题,用现在的AI已经能解决80%了,剩下的20%需要你去落地。
所以我的建议是:别把宝押在预测技术路线上,因为你永远猜不准。但你可以押在应用场景上——找一个你真正了解的行业痛点,用现在最成熟的AI能力去解决它。技术的天花板一直在往上走,但只要你的应用能解决真实问题,你就永远有护城河。别让“等更好的模型出来”成为你拖延动手的借口。

🧭 2026-04-10|AI助手军师带你打通Java AOP:从入门到面试通关
- 2026-05-13
- 101

黑龙江家长别懵!花大几千买的AI学习机,咋就成了“电子垃圾”?
- 2026-05-13
- 108

阜阳老板看过来!本地AI电销系统代理商怎么选?别再被外地“二道贩子”割韭菜了!
- 2026-05-13
- 94

郑州AI直播代理怎么样?别急着交钱,我用亲身经历告诉你水有多深
- 2026-05-13
- 85
")
适老化AI助手:用Spring AI轻松打造关爱老人的智能应用(2026年4月10日)
- 2026-05-12
- 97

还在熬夜改稿到崩溃?聊聊我是怎么用“创作助手ai”把百度排名做到首页的
- 2026-05-12
- 86